物理・情報科学科 韓 先花 先生
近年さまざまな応用がされている機械による深層学習。この技術で一体どのようなことができるのか、この分野の研究がどのように行われるのかを伺いました。

韓 先花 Xian-Hua HAN
山口大学大学院創成科学研究科 准教授
学域:理学系学域(情報科学分野)
学科:物理・情報科学科
研究室HP:http://mlp.sci.yamaguchi-u.ac.jp/
インタビュアー(以下、イ):今回のインタビューは物理・情報科学科の韓先花先生です。
研究室の学生の皆さんにも後ほどお話を伺わせていただきたいと思います。よろしくお願いします。
韓先花先生:よろしくお願いします。
 |
 |
 |
 |
| 韓先花先生(以下、韓) | 山道航平さん(以下、山) | 中井克啓さん(以下、中) | 寄元康平さん(以下、寄) |
山・中・寄:よろしくお願いします。
機械の視覚知能化
韓:一言でいえば機械の視覚知能化です。
機械に人間のような学習能力を持たせ、人間の視覚や脳を高レベルで工学的に模倣する人工知能システムを作り出すことを目標としています。
例えば、多種多様な情報センサーで得られた膨大なデータから自ら規則性を学習する機械学習システムや統計的解析技術の理論開発を用いての画像認識、超解像度の研究、更に医療支援システムなどへの応用研究も行っています。
イ:難しいですね.具体的にはどういったことを?
韓:そうですね。例えばここで行っている機械の視覚知能化の研究に、画像理解・物体検出というものがあります。
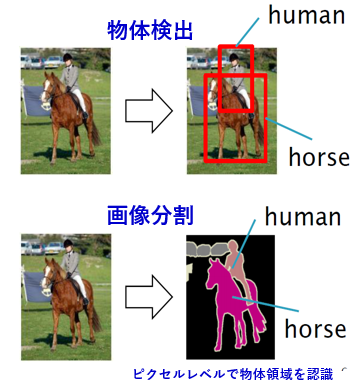
撮影された画像に写っている人・動物・車といったものを機械に自動検出させるものです。例えば人と馬が写っているこの画像(真ん中)で、”人”と”馬”を機械が検出して、矩形で囲って示しています。人には何がどのように写っている写真か無意識に理解できますが、ドットの集まりである写真画像において、どの領域が”馬”か”人”か”背景”かを機械に判別させるのは難しいです。
このように(下の方)”人”と”馬”をピクセルレベルで塗分け、更に”人”が”馬”に乗っていると認識させる。このように人間が視覚で瞬時に判別することを機械が判断できるようにする。これが視覚知能化です。
イ:機械が画像を判断できると、どんなことができるようになりますか?
韓:同じ犬種でも見た目にかなりバリエーションがあって、よく似た犬種もある、こういう犬の写真は犬種の判別がかなり難しいでしょう?
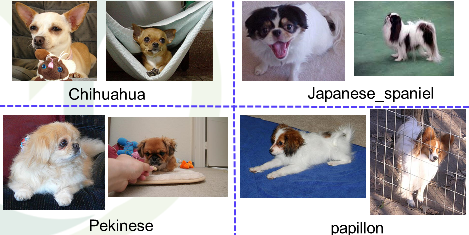

イ:そうですね・・・色や毛のボリュームで違う種類の犬の方がむしろ似て見えたりして・・・犬好きさんでも区別は厳しいのではないでしょうか。
韓:写真の写り方による印象の違いもありますから、相当詳しくないと難しいと思います。こういった犬の写真を機械に入力して犬種を特定させるという研究に2018年度の学生が取り組みました。
イ:機械が写真から犬種を当てるのですか。それで!?
韓:学習させたコンピュータに10 枚中9 枚を正しく識別させました。
イ:9 割!すごい。
|
|
 |
 食事画像を撮影するだけで摂取カロリーと栄養を計算させるといった取り組みもあります。 食事画像を撮影するだけで摂取カロリーと栄養を計算させるといった取り組みもあります。 |
 |
|
|
|
|
韓:機械の視覚知能化の技術を使ってこういったことができるのです。
機械にどうやって物体を認識させるか
韓:2、30 年前からある一番簡単で一般的な識別手順としては、例えばリンゴの場合で、リンゴの特徴は赤色であることを足掛かりに”リンゴである”という判断に導くなら、画素の集まりである画像から、どこまでが対象物かをまず判断。そして赤く見えるリンゴでも詳細に見ればオレンジや緑もあるので、各色の量・割合を抽出して対象物がリンゴ色であるかどうかを判断する。これが一番簡単な例です。
イ:色で判定するだけでも大変そうですね。
韓:はい。しかもミカンの場合・・・栗の場合・・・と全てにこういった判定式が必要になるので、人がこれを作るのにはあまりに大変なな作業になります。そこで、この判定式を機械自身に作らせようという試み、これが機械に学習させるということです。自分たちの研究の一番基となる部分がこれなのです。

イ:学習・・・色のパターンを機械に自動収集させるということですか?
韓:色に限りません。画像をそのまま機械に学習してもらうことで特徴そのものを機械に探させるのです。
人間はそれがリンゴかミカンかを瞬時に識別します。小さい頃から数多く見て脳が学習してきているからですよね。少々形が変わっても赤くなくてもリンゴと理解できます。
機械学習も同じように行います。
例えばリンゴとミカンを識別させる為に、様々なリンゴの画像を”リンゴ”というラベルと共に、ミカンの画像には”ミカン”のラベルと共に機械に与える。このように人間が感覚で自然に行っている情報収集と同じようにどんな画像がリンゴであるか機械が自動学習するのです。
イ:機械が人間のように特徴自体を自動認識する・・・イメージは分かりましたがそんなことができるのですか・・・
韓:コンピュータ自身が画像の特徴となる情報を様々な角度から何層にも抜き出し、これを自動的に学習する深層学習という手法です。沢山の画像を読み込ませることで機械自身が対応タスクの(数理)モデルを学習するのです。
イ:目的に応じて作られたモデルを、研究者がパラメータ調整して精度を上げるという研究手順ですか?
韓:機械が自動的にパラメータを調整してくれるのが機械学習です。何百万というパラメータがあるのですから人ではとても(笑)。
我々の研究室ではこのような機械学習手法や学習手順などの検討を行い、様々な応用に適応し、実験・検証という形での研究をしています。
具体的に取り組んでいる研究内容を教えてください
▪画像の降雨ノイズ除去
 山:山道航平です。自分の研究は高速且つ高精度に降雨ノイズ除去を行う新たな深層学習ネットワークの開発です。
山:山道航平です。自分の研究は高速且つ高精度に降雨ノイズ除去を行う新たな深層学習ネットワークの開発です。
自動運転や監視カメラ等にとって日常的に起こる雨の存在は大きな障害になるので、雨天時の画像には前処理として雨ノイズを取り除きノイズ箇所を復元する手法が必要になります。例えばノイズを混ぜたこの画像・・・
イ:雨どころじゃない(笑) 引っかき傷でぐちゃぐちゃですね
山:この画像をコンピュータに処理させて、ノイズを除去した画像を生成します。
ノイズのある部分を自然に着色補正させるために、コンピュータにノイズ入りの画像とノイズ無し画像を学習させました。この為に使用した画像は1800 枚くらい。機械学習分野では少ないほうですが、それでもコンピュータ回しっぱなしで1-2 日は学習にかかっています。より効率的に、かつ高精度の結果を出力できるよう試行錯誤を行っているところです。
様々な手法を比較したものがこれです。
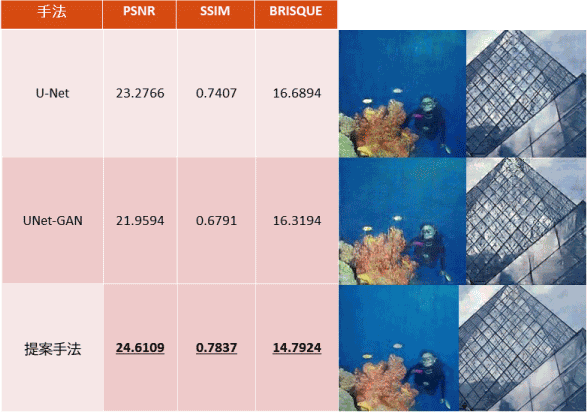
イ:こうして並べてよく見ると手法によって結果に差がありますね。
山:自分としても新たな手法を提案し、従来手法より高精度の結果を得ることが出来ました。そして更に、一旦出力した結果をフィードバックさせる手法でよりクリアにより自然な結果を出すことに成功しました。
この研究で難しいのは完成度の評価基準なのです。
人間の感覚では信憑性に欠けます。そう言われても・・・って思うでしょう?評価を数字で表す必要があるので、その評価の仕方も議論されているので、自分も何種類かの評価方法で結果の評価を試みています。
イ:ここにあるのは、どういった基準の評価なのですか・・・?
 韓:表の左二つは定量基準での評価、一番右は人間から見た評価(視覚評価)を表すものと言えます。評価方法はいろいろありますが、目的によっても使う評価基準は変わりますから、どのような評価方法が一番よいかがまだ議論されているところなんです。
韓:表の左二つは定量基準での評価、一番右は人間から見た評価(視覚評価)を表すものと言えます。評価方法はいろいろありますが、目的によっても使う評価基準は変わりますから、どのような評価方法が一番よいかがまだ議論されているところなんです。
山:コンピュータの画像の色は赤緑青の各色を0~255 の値で指定した色バランスで出来てます。このPSNRという評価項目は、生成された結果色と目標色の数値差を用いて計算したピーク信号対雑音比で、大きいほど完成度が高いということです。値が1 違うと大違いです。
イ:SSIM というのは?
山:より人間が感じる違いに近いものを機械が判じている値です。大きいほど良い。
イ:こちらのBRISQUE は?
山:実際にノイズ有画像と無し画像の比較テストを人で行った結果統計データから作られた評価数値です。
一番人間の感覚に近いものといえるでしょう。人間の感覚に近いほど値は小さくなります。3 違うとはっきり分かります。
 イ:山道さんの提案手法は色合いコントラストがかなりいい感じになっていますね。数値もそれを表していて十分な成果が得られているようですね。完成ですか?
イ:山道さんの提案手法は色合いコントラストがかなりいい感じになっていますね。数値もそれを表していて十分な成果が得られているようですね。完成ですか?
山:元画像しだいで別の手法の方が良い結果になるものもあります。全てにOK の手法とはなかなか・・・研究者により様々な試行が行われているところです.自分も、これまでの降雨ノイズ除去は雨の部分をいかに着色するかという視点で作っていましたが、今は雨部分を引くというアプローチでもっと良い結果が得られるのではないかと考えて研究を進めているところです。
イ:まだまだ継続中なんですね。更に良い結果が出ることを期待しています。
山:雨だけでなく様々な種類のノイズに対応できるので、監視カメラ等のザラついた映像をクリーンにしたり、雨以外にも視界を妨げるもの排除したい時などに生きてくる技術です。頑張ります。
▪航空写真からの物体の検出と分類
 中:中井克啓です。物体の検出をやっています。
中:中井克啓です。物体の検出をやっています。
写真の中の椅子や車・飛行機などがどこにあるかを四角い箱で囲って示し、箱左上のラベルに識別した名称を表示させるという形で検出をしています。
例えばこの画像の場合、ピンクの箱で人を、黄色い箱で自転車を見つけています。
イ:魚自転車(笑)!?すごいですね。これを機械は自転車って判断できたんですか?
中:タイヤやペダル・チェーンとかで判断してるんでしょうね。
イ:”してるんでしょうね”・・・て?そうか、機械自体が特徴を捉えて判断するんでしたね!
中井さんの研究テーマは何の検出ですか?
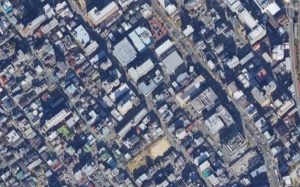 中:自分は深層学習を用いて、航空写真から車両を検出する手法の開発を行いました。
中:自分は深層学習を用いて、航空写真から車両を検出する手法の開発を行いました。
航空写真に写る車を自動検出して車種を識別したり台数をカウントしたりといったことをします。
イ:ごちゃごちゃしてる上に荒い画像で車かどうかも判断しづらいですね。
中:普通の画像に比べると航空写真画像は画質が低く、写っているもの全てが小さい上、駐車場や渋滞の現場だと車が密集しているので更に検出が難しくなります。一般画像での物体検出では、チェーンやペダルといった特徴を見つけることで自転車であると判断するのですが、航空写真ではそういう特徴となる部分がとても小さく判別が難しい。それをいかに行うかという研究です。
イ:沢山の車がしっかりと検出されてますね。フレームの色違いは何を表すものですか?
 中:車種の違いを分けています。
中:車種の違いを分けています。
イ:この細かさで車種まで!?
車種まで事前に学習させているということですね。
中:深層学習には事前学習に、かなり大規模なデータの準備が必要です。自分の場合も様々な車種の画像を何千枚何万枚と学習させています。
イ:そんなに!
中:学習には時間がかかりますが、学習を終えたら完成したモデルに画像を与えるだけで瞬時に結果を出してくれます。
イ:どんなところが難しかったですか?
中:物体検出は、先ほどの人や魚自転車を囲んでいたような大小様々な箱を画像の中に当てはめるようにして行います。航空写真は一般写真と比べて写っている物体全てが細かいので、検出対象物に合わせた箱サイズの調整、物体の重なりが分かりづらいものは検出ピッチの調整などが必要になります。プログラム自体が複雑で大きいので調整にはかなり時間がかかります。
そして精度に加え検出速度の向上も目指しています。動画に対応させるなら尚更これが重要になりますから。
なるほど、航空写真から目視で車をカウントなんて気が遠くなりそうです。瞬時に機械が見つけてくれるとありがたいですね。
イ:この研究はどのような利用ができるでしょう?
 中:航空写真は道路や鉄道などの交通情報管理やインフラ整備、災害等緊急時の状況把握などに用いられていますが、航空写真上の物体を人の目で検出・解析を行うことは非常に困難かつ非効率的です。車の分布数が瞬時に取得できれば渋滞原因の手掛かりがすぐに得られ、交通情報管理に役立てられる。インフラ整備の助けにもなるでしょう。
中:航空写真は道路や鉄道などの交通情報管理やインフラ整備、災害等緊急時の状況把握などに用いられていますが、航空写真上の物体を人の目で検出・解析を行うことは非常に困難かつ非効率的です。車の分布数が瞬時に取得できれば渋滞原因の手掛かりがすぐに得られ、交通情報管理に役立てられる。インフラ整備の助けにもなるでしょう。
災害時においては、災害箇所の航空写真で、ここに人がいる、車があるということが機械で検出されれば迅速な救助を可能にするし、災害箇所が瞬時にピックアップできれば災害対応にも大きな力になると思います。
▪画像キャプションの自動生成
寄:寄元康平です。機械が写真画像の内容を理解して、写真の説明文章を自動生成するという研究をしています。
イ:画像から機械が文章を作るのですか!
寄:画像中の人や物、位置、姿勢、色といった情報を様々な角度から機械が収集し、画像の特徴情報をまとめたものを特徴マップといいます。この特徴マップから情報を引き出しながら文章を生成します。
イ:例えば・・・”これは馬の写真です”って感じですか?
寄:従来手法はこの特徴マップから人や物の存在だけを取り出しての文章生成だったのでそういった感じでしたが、位置関係を維持した形で情報を取り出せるようにできたので周辺状況を盛り込んだ形での文章生成ができるようにまりました。
イ:では、どんな感じの文章ができますか?
寄:かなり人が作った文章に近いものができてきています。
例えばこの男性がギターを弾いてる写真ですが、これを機械に入力すると”男がギターを弾いている”と文章が生成されています。

 イ:かなり高度な文章が出来てますね!
イ:かなり高度な文章が出来てますね!
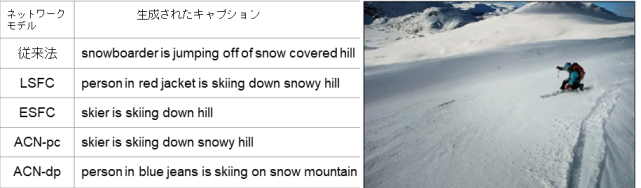
寄:精度も上げられています。色々な手法が多くの人に試されていますが、こちらのスキー写真を見てください。このスキー写真へのキャプション付けでは”スノーボードをやってる”という文章が生成されてきてます。が、これはちょっと間違いですね。
でも自分が提案した4 つの手法ではどれも”人はスキーをしてる”と捉えてられている。勿論まだ十分でないところもあるのですがこの写真の主語が”スキーしてる人”と捉えられたのは自分としてはポイントです。精度が上がったといえるでしょう?
イ:これにはどれくらいの画像データの学習が必要でしたか?
寄:そうですね、少ないケースでも8000 枚。多ければ十数万枚の学習が必要でした。
イ:途方もない量ですね。
これには画像内の物体の高精度の認識検出に加えて物体間の関係・状況の判断が必要です。更に、より自然な文章を作る為に、単語の順番・表現といった言語処理分野の学習も必要になります。
寄:文章の作り方には様々なバリエーションがありますから、様々なパターンの文章と対応する画像とで結果的に膨大なデータ量になるんです。
イ:学習数の違いで結果に差が出ますか?
寄:学習数が多いと表現力が上がります。より自然な表現ができる。評価の違いにも現れています。
イ:学習時間はどれくらいにかかるのですか?
寄:1,2 週間ですね。学習データを入力したらコンピュータが連日学習を行い続けます。特に卒論準備時などはずっと動きっぱなしでしたね。
イ:まだ終わってないな、まだ動いてるなって見守り続ける日々ということですね。
|
寄:そう・・・なのに途中でプログラムのミスが発覚したり変更があったりすると・・・ああああ止めなきゃ!これ違うぅぅぅ!って イ:あぁ(^^; ・・・想像するだけで辛そう 寄:ため息ばかりでしたよ。 イ:学習が終わっていれば瞬時に結果が返って来るということではありますが、それまでの試行錯誤は相当大変そうですね。 |
山・中:本当にもう(笑) |

寄:いろいろ使い道があると思いますが,例えばSNS に写真を投稿したらキャプションを自動で付けてくれる なんて面白いんじゃないでしょうか?
あるいは周辺状況を自動的に理解した上での対話システムの開発ができれば,視覚的障碍者への支援などに役立てることができるかもと思っています.
イ:ものすごく応用が広いのですね.
医療分野への応用(韓先生)
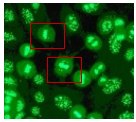 韓:臓器の組織細胞の種類で免疫力が量れるものがあります.画像の中から目的の細胞を見つけ出すことで体の状態を解析して疾患を判明させられるのです.・・・とはいえ人の目で細胞を一つずつ観察するのは… (画像:Hep-2細胞Stainingパターン認識)
韓:臓器の組織細胞の種類で免疫力が量れるものがあります.画像の中から目的の細胞を見つけ出すことで体の状態を解析して疾患を判明させられるのです.・・・とはいえ人の目で細胞を一つずつ観察するのは… (画像:Hep-2細胞Stainingパターン認識)
イ:想像するだけで気が遠くなりそうですね.このピックアップされている細胞は周囲のものとは違う種類ということですか?うーん・・・私では違いがよく分かりませんが,このように機械なら即時に検出できるということなのですね.
▪医療画像解析
韓:医者はCT,MR,レントゲンといった医療画像データを吟味して病変部分を特定しますが画像の全てを隈なく精査(読影)するのは大変時間がかかります。
そこで前処理として医療画像を深層学習させた機械に病変と思われる箇所を着色表示させ、機械がピックアップした場所を医者が重点的にチェックすれば医者の負担軽減ができます。最終判断を医者が行うことは絶対ですが、効率よく診断が進められるでしょう。
 イ:素晴らしいですね。この為には機械に沢山の医療画像を学習させなければなりませんね。
イ:素晴らしいですね。この為には機械に沢山の医療画像を学習させなければなりませんね。
韓:医療画像データの収集に加え、更に病変部分の見え方の特徴を医者の経験を基に聞き、この定量化を行うことが必要です。
イ:定量化とは?
韓:これを機械で処理できるよう数値で表現するということです。
肺気腫の有無はCT 画像の読影で判別しやすく、ピクセルレベルでの判別が可能です。
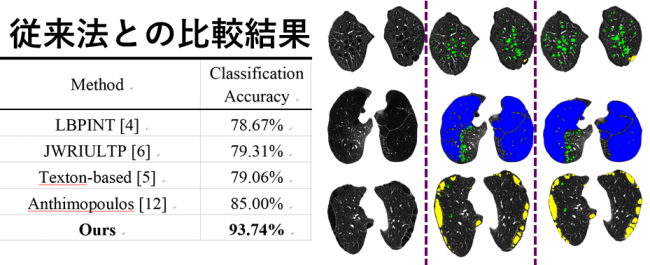
こちらの画像が実際の肺気腫症の検出結果です。
イ:色付きのところが検出した肺気腫ということですね。
韓:同時に別種の肺気腫が並存するケースもあるので。肺気腫の種類で色分けして検出表示しています。
イ:しっかり見つけて塗分けられてますね・・・あ、でもちょっと塗りが違うところがありますね。
韓:これまで提案されてきた検出手法の組合せや扱い方を変えたりして最善の手法を考、精度を比較します.私もいくつかの手法の提案をし従来法と比較していますが,ケースによって検出
精度が変わります。すべての症例に対してうまく行く手法の開発はなかなか難しいですが、大量データと機械学習技術のおかげで精度は上がってきています。
▪臓器のセグメンテーション
 |
| 肝硬変支援診断 |
韓:臓器のセグメンテーションも可能です。
イ:セグメンテーション?・・・分割?
韓:CT,MR の2 次元画像に写る臓器の中から目的とする臓器部分のみを取り出し、3 次元に構成し臓器のモデルを作るものです。これは様々な応用が期待出来ます。
例えば肝硬変は肝臓の形状に特徴が出るので、3D モデルを作ることで診断が容易になります。
血管のセグメンテーションを行うCAS(手術支援の解析・可視化システム)は、深層学習により、隅々まで血管が巡らされている臓器である肝臓内部の血管を抽出し、チューブ構造そのままの状態でモデル化を行います。
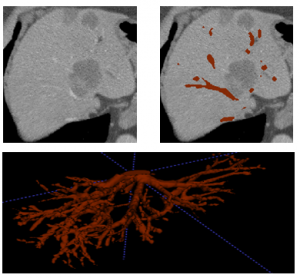 |
| 肝臓から血管の抽出 |
肝臓内の血管位置は病変位置や種類特定の大きな手掛かりですが、2D 画像で、3D に広がっている血管の位置の把握は困難です。
CT,MR 画像から血管の分布をピクセルレベルの3D で可視化することは、最善の手術方法をセレクトし、大きな血管を避けるなど効率の良い手術を行う為のサポートになるでしょう。
勿論、その為には予め医者の経験に基づく膨大なラベル付きの画像や情報の提供を受け、これを機械に学習させる必要がありますが、こういった機械学習による医療支援システムは医療画像から得られる情報の把握を効率的に行い、医療の専門家の施術精度を上げ、医療処置の効率を上げる助けになるでしょう。
イ:本日は興味深いお話をありがとうございました。
インタビュー日:2020年3月25日